- Apie LMA
-
Dokumentai
- Teisinė informacija
- Statutas
- Strateginis veiklos planas
- LMA narių rinkimų reglamentas
- Reikalavimai renkamiems nariams
- Prezidiumo rinkimų reglamentas
- Užsienio narių iškėlimo tvarka
- Pareigų paskirstymas
- Finansinės ataskaitos
- Viešieji pirkimai
- LMA norminiai vietiniai teisės aktai
- Bendradarbiavimo sutartys
- Mokslininko etikos kodeksas
- Sudėtis
-
Veikla
- LMA veiklos ataskaita
- LMA narių visuotiniai susirinkimai
- Rinkimai
- LMA leidyba
- Informacinis leidinys „LMA žinios“
- Premijos ir stipendijos
- Tarptautiniai ryšiai
- Baltijos šalių intelektinis bendradarbiavimas
- Skyriaus „Mokslininkų rūmai“ veikla
- Bendradarbiavimas su regionais
- LMA ir akademikai žiniasklaidoje
- ES SF parama LMA
- Renginiai
- Knygos
- Jaunoji akademija
-
LMA COVID-19
- Komisija
- COVID-19 Santrauka
- Trumpos žinios
- COVID-19 Virusologija
- COVID-19 Epidemiologija ir modeliavimas
- COVID-19 Imunologija, diagnostika
- COVID-19 Klinikiniai aspektai
- Vaikų, nėščiųjų ir žindyvių COVID-19
- COVID-19 Gydymas
- COVID-19 Profilaktika ir skiepijimai
- Nuorodos į informaciją, susijusią su COVID-19
- Konkursai
Naujienos
Dirbtinis intelektas – naujos galimybės
2023 03 28
Kovo 23 d. Lietuvos mokslų akademijos (LMA) skyrius „Mokslininkų rūmai“ daugiau nei 600 šalies gimnazistų ir jų pedagogų pakvietė į nuotolinę LMA Technikos mokslų skyriaus pirmininko akademikoGintauto Dzemydos paskaitą„Dirbtinis intelektas – naujos galimybės“.
Paskaitą akademikas pradėjo pristatydamas Vilniaus universiteto (VU) Matematikos ir informatikos fakultete esantį Duomenų mokslo ir skaitmeninių technologijų institutą, kuriam pats ir vadovauja. Šiame institute vykdomi tyrimai dirbtinio intelekto (DI) ir su juo susijusiose srityse. Akademikas pakvietė gimnazistus baigus mokyklą stoti į VU, VDU, KTU arba VILNIUS TECH studijuoti informatiką – bene populiariausią šiuo metu specialybę.
Norėdami pasinaudoti DI, sakė lektorius, mes turime maitinti jį duomenimis. Tam yra sukurtas ištisas duomenų mokslas, kuriame ir yra tiek pats DI, tiek jį sudarančios dalys. Pastaruoju metu dėl nepaprastai sparčiai augančio duomenų kiekio, galime spręsti labai daug įvairių uždavinių. Bet atsiranda problema tuos duomenis apdoroti. Čia į pagalbą galima pasitelkti didelio pajėgumo kompiuterį, kurį galima išmokyti duomenis klasifikuoti, nustatyti dėsningumus, rasti ryšius tarp atskirų duomenų grupių, iš didelių duomenų aibių išgauti svarbią informaciją. Tai vadinama duomenų tyryba. Akad. G. Dzemyda išsamiai papasakojo, kaip sprendžiami genetinių duomenų tyrybos uždaviniai. Tarkim, žmogaus polinkį į nutukimą lemia genų mutacija, atsiradusi evoliucijos eigoje, kai organizmui buvo aktualu kuo ilgiau išlaikyti riebalus, kad išgyventų nepritekliaus sąlygomis. Mūsų laikais, kai maisto turime užtektinai, žmonėms, turintiems tą pakitusį geną, gresia nutukimas, diabetas ir pan. Čia duomenų tyrybos uždavinys yra nustatyti, kur yra pakitusi nukleobazių seka, turinti įtakos ligai.

Apdoroję turimus objektyviai egzistuojančius duomenis, gauname informaciją – duomenis, pateiktus mums reikiamu būdu ir susietus su tam tikra problema ar sprendimu. Tą informaciją apdorodami, interpretuodami tam tikrame kontekste, gauname žinias, reikalingas sprendimams priimti ir veikti (pvz., skirti tam tikrą gydymą konkrečiam pacientui).
Akademikas papasakojo apie šiuo metu, pasitelkiant DI, sprendžiamą uždavinį – donoro parinkimą kepenų transplantacijos operacijoms. Sukaupus didelį kiekį precedentų (atliktų operacijų) ir žinant jų sėkmę, galima „apmokyti“ kompiuterį rekomenduoti gydytojui sprendimus, kuriuos DI padaro įvertinęs po keliasdešimt tiek donoro, tiek paciento požymių ir apskaičiavęs paciento išgyvenamumo po operacijos trukmę.
Lektorius trumpai aptarė duomenų tyrybos uždavinių tipus: duomenų klasifikavimo (priskyrimo klasėms), klasterizavimo (suskirstymo į grupes), prognozavimo, dažnų struktūrų paieškos, daugiakriterinių sprendimų, rekomendacijų, vaizdų analizės ir kt. bei pateikė pavyzdžių iš medicinos srities.
Duomenų mokslą sudaro daugybė tarpusavyje susijusių sričių, teigė akademikas, ir vaizdžiai parodė, iš ko jis susideda.
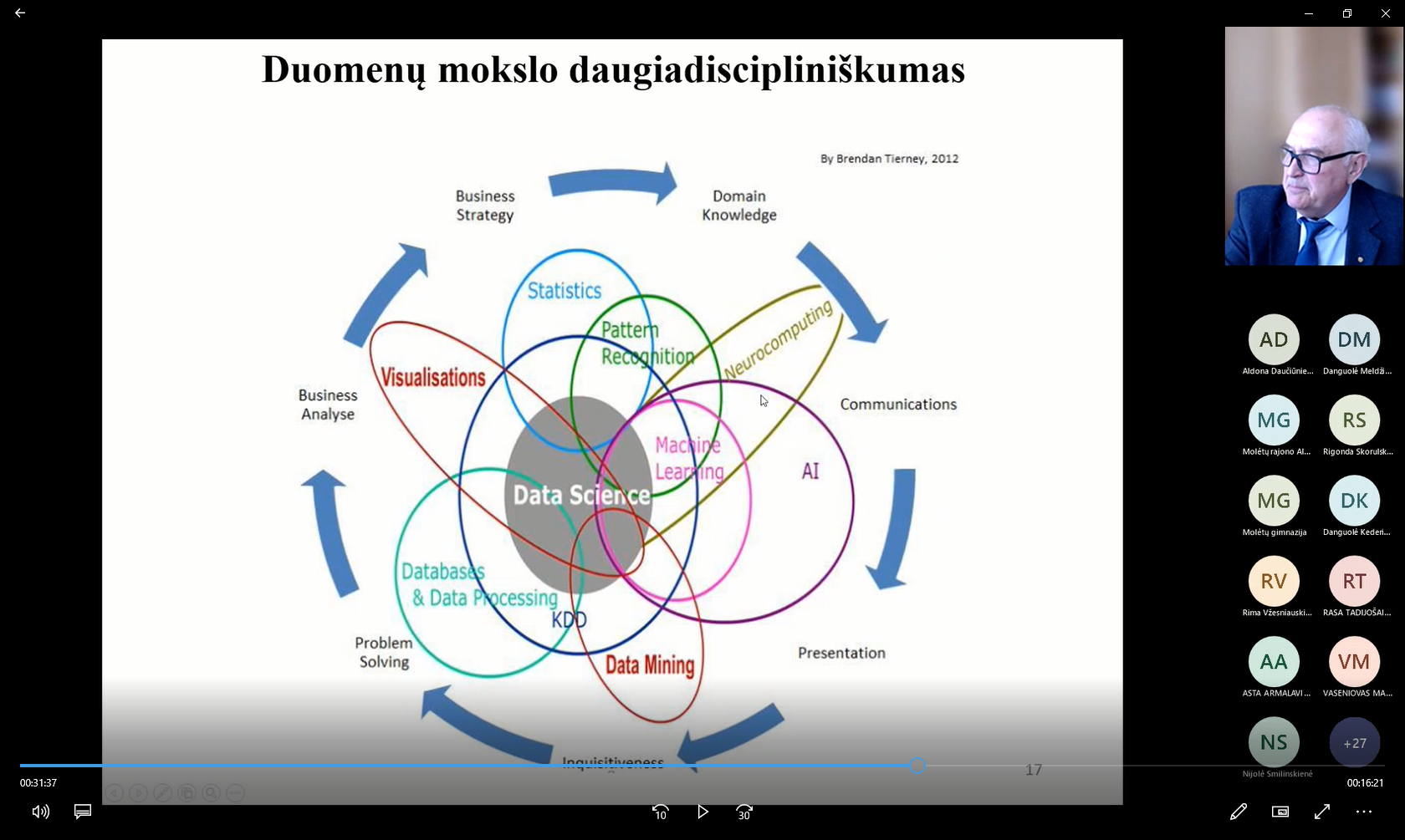
Mašininis mokymasis – tai duomenų mokslo sritis, suteikianti kompiuteriams galimybę mokytis be aiškių instrukcijų. Tai DI forma, leidžianti sistemai mokytis iš duomenų. Mašininio mokymosi modelis – tai išvestis, atsakymas, (pvz., serga žmogus ar ne), gaunama apmokius mašininio mokymosi algoritmą su duomenimis.
Neprižiūrimojo mašininio mokymosi (unsupervized machine learning) atveju DI tiesiog rodoma daugybė duomenų ir jis pats išmoksta atrasti informacijos panašumus ir skirtumus. Toks būdas yra puikus sprendimas tiriamųjų duomenų analizei, klientų segmentavimui, vaizdų ir šablonų atpažinimui ir pan. Prižiūrimame mašininiame mokymesi (supervized machine learning) naudojami pažymėti duomenų rinkiniai algoritmams mokyti (pvz., DI rodomos organo nuotraukos ir pasakoma, kuriose iš jų yra vėžys, kuriose ne). Sustiprintas mašininis mokymasis (reinforcement machine learning) – panašus į prižiūrimąjį, tačiau modelis mokosi eigoje, naudodamas bandymus ir klaidas. Gilusis mokymasis – mašininio mokymosi algoritmų klasė – tai sudėtingi neuroniniai tinklai, turintys daug įvairaus tipo blokų, išmokstantys spręsti klasifikavimo, atpažinimo ir kitus uždavinius. Dažniausiai taikomas apdorojant ir analizuojant vaizdus, garsus arba signalus.
DI pasitelkia kompiuterius ir mašinas, kad imituotų žmogaus proto gebėjimus spręsti problemas ir priimti sprendimus. DI vertinimui naudojamas Tiuringo testas, nustatantis mašinų gebėjimą demonstruoti intelektą. Jei per 5 minutes bendraudamas negali atpažinti, kad kalbiesi ne su žmogumi – tai tokį kompiuterį jau galima laikyti „mąstančiu“.
Lektorius pateikė populiarius DI pavyzdžius (IBMʼs Deep Blue DI 1997, prie šachmatų lentos nugalintis Garį Kasparovą; automatiškai valdomi automobiliai; balsu valdomi sprendimai), įvardijo sritis, kuriose DI jau plačiai taikomas (pramonė, robotai, transportas, medicina, kompiuterinė rega, satelitinių vaizdų analizė, finansai, muzika ir kt.). Papasakojo ir vaizdžiai parodė, kaip naudojama dabar jau gerai išvystyta giliųjų klastočių (deepfake) technologija, kurią naudojant galima pakeisti, pvz., žmogaus veidą ar balsą. Pateikė sėkmingų tinklų pavyzdžių (LeNet, AlexNet, ZF Net, ResNet, GoogleNet / Inception), papasakojo apie drauge su savo doktorantu sukurtą Inception taikymo pavyzdį – emocijų atpažinimą nuotraukose.

Baigdamas paskaitą akademikas G. Dzemyda pakvietė klausytojus apsilankyti VU Duomenų mokslo ir skaitmeninių technologijų instituto tinklalapyje ir plačiau susipažinti, kuo dar užsiima jo vadovaujamas institutas.
Parengė LMA skyriaus „Mokslininkų rūmai“ vyriaus. specialistė Diana Lekevičienė